Sync Airflow database
It is now possible to synchronize the Datacoves Airflow database to your Data Warehouse
note
This is currently only available for Snowflake and Redshift warehouses.
Data Sync Decorator
To synchronize the Airflow database, we can use an Airflow DAG with the Datacoves Airflow Decorator below.
@task.datacoves_airflow_db_sync
To avoid synchronizing unnecessary data, the following Airflow tables are always loaded. Where possible, these are loaded incrementally for higher performance:
ab_permissionab_roleab_userdag(incrementally loaded by last_pickled)dag_run(incrementally loaded by execution_date)dag_tagimport_error(incrementally loaded by timestamp)job(incrementally loaded by start_date)task_fail(incrementally loaded by start_date)task_instance(incrementally loaded by updated_at)
The decorator can receive:
db_type: the destination warehouse type, "snowflake" or "redshift"connection_id: the name of the Airflow Service Connection in Datacoves that will be used by the operatortables: list of additional tables to loaddestination_schema: the destination schema where the Airflow tables will end-up. By default, the schema will be named as follows:airflow-\{datacoves environment slug\}for exampleairflow-qwe123
Example DAG
from pendulum import datetime
from airflow.decorators import dag, task
@dag(
default_args={
"start_date": datetime(2026, 1, 1),
"owner": "Bruno",
"email": "bruno@example.com",
"email_on_failure": False,
"retries": 3
},
description="Sample DAG for dbt build",
schedule="0 0 1 */12 *",
tags=["extract_and_load"],
catchup=False,
)
def airflow_data_sync():
@task.datacoves_airflow_db_sync(
db_type="snowflake",
destination_schema="airflow_dev",
connection_id="main",
# tables=["additional_table_1", "additional_table_2"],
)
def sync_airflow_db():
pass
sync_airflow_db()
airflow_data_sync()
note
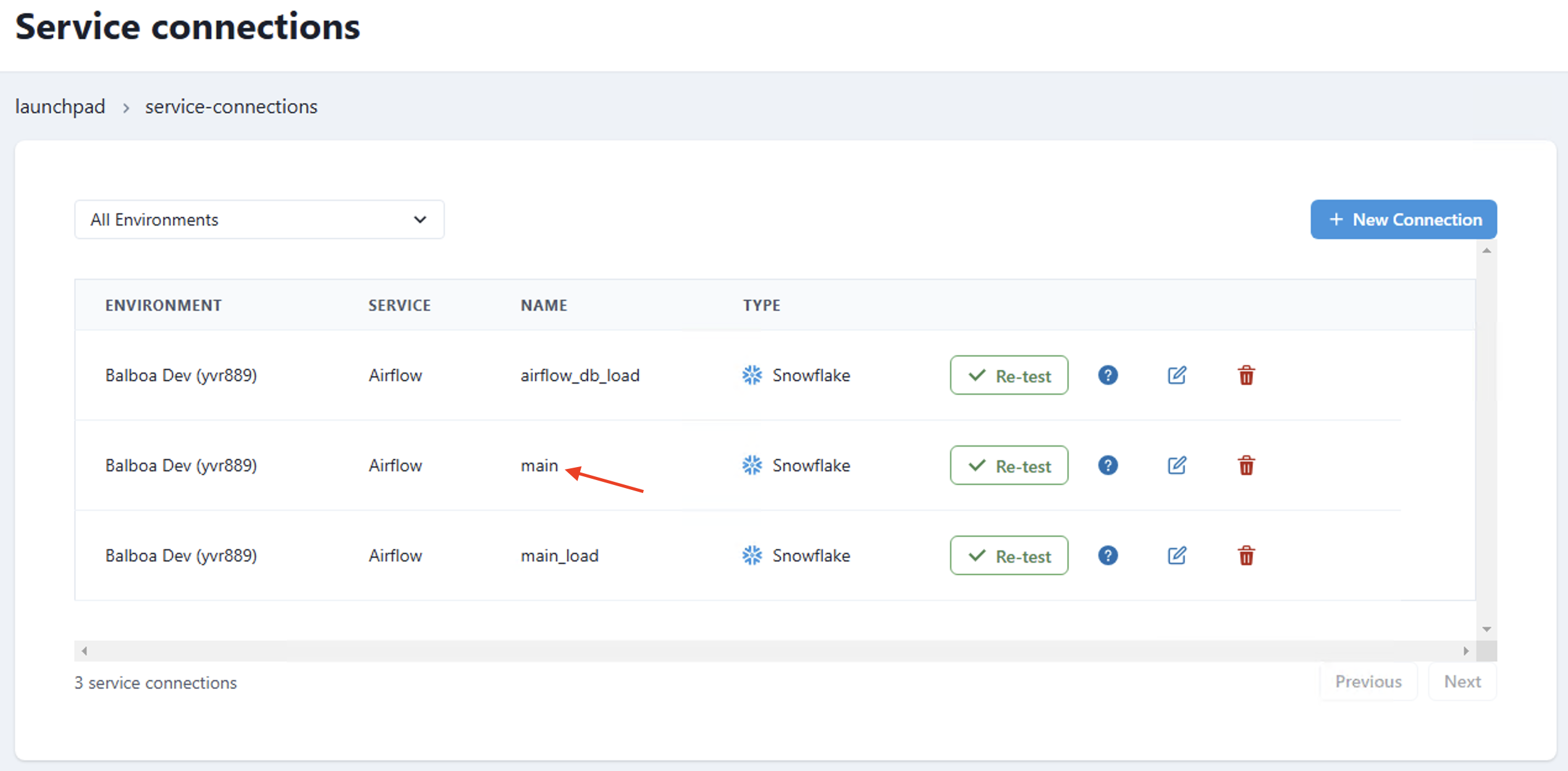
The example DAG above uses the service connection main