How to develop and release a feature
Releasing a feature into production involves following a development process utilizing Github and GIthub Actions to run automated scripts along with human in the loop approvals as gates to move to the subsequent phase of deployment.
The high-level process is shown below.
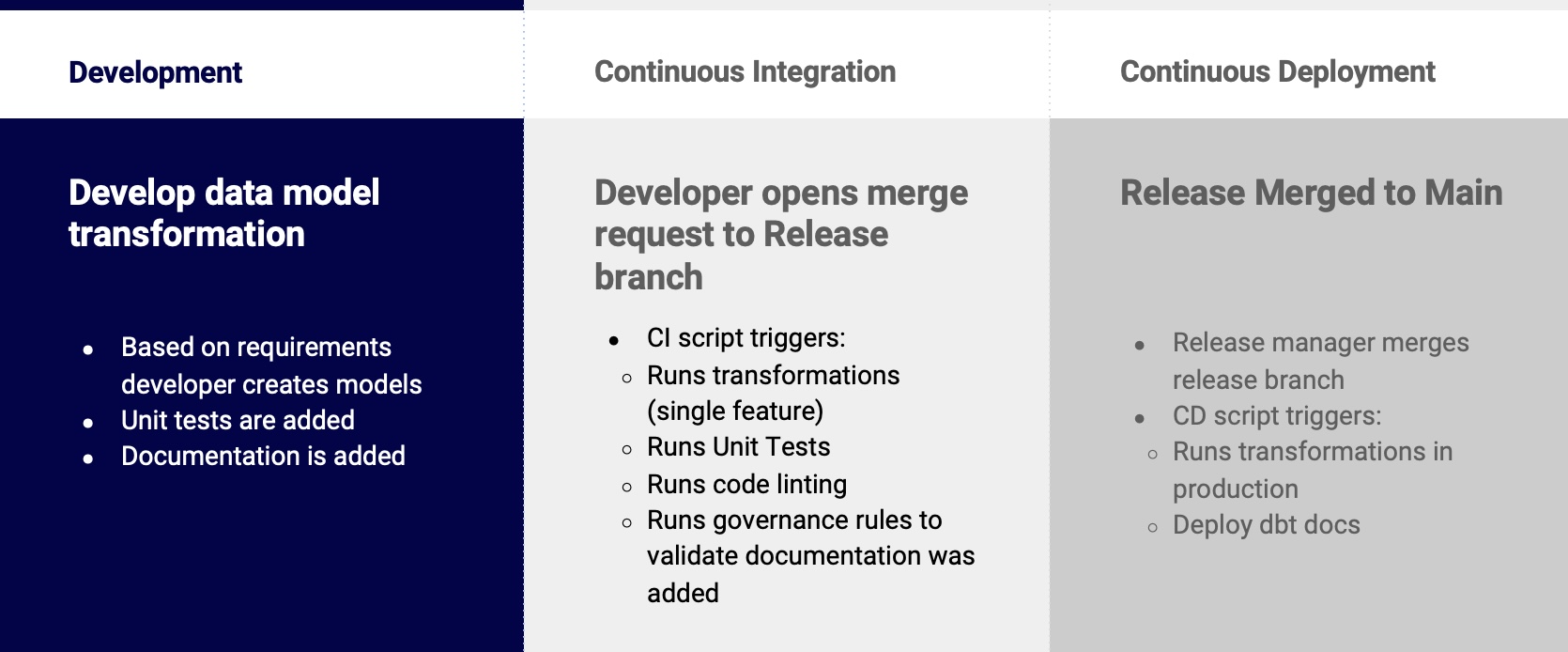
Development and Release cycle
-
Development
- Create a feature branch from the Main branch to start a new feature
- Add files with your SQL, run your dbt models and validate the query results
- Add documentation to clearly describe the models and their columns
- Add unit tests in your yml files to prove the agreed outputs are delivered and ensure data integrity
- Commit and push the new branch to Github
-
Merge Request
-
In Github, create a pull request from the feature branch
-
CI Automation: Checks are run to ensure code style and documentation requirements are met:
- A new database is created for each Pull Request
- Production manifest.json is downloaded
- A dbt build is executed building only the changed models and their dependencies along with tests
- Developed code is checked against configured SQLFluff linting rules
- Governance tests are run using dbt-checkpoint
- Airflow checks are performed
-
Code Review:
-
Team members review submitted code to confirm:
-
Delivered code satisfies task requirements
-
Any new models / columns are appropriately named
-
Security has been applied correctly to any tables created by dbt
-
Documentation is of a sufficient quality to allow future use
-
Tests are appropriate for the model
-
Approve merge request or provide feedback to developer for further improvement
-
Continuous Delivery
-
CD Automation:
-
A staging database is created by the blue/green deployment process by cloning the production database
-
All changed models and their dependencies are created and tested in staging database
-
If all tests pass, the staging database is swapped to become the production database and the old production database is dropped
-
Merged pull request databases are dropped
-
dbt documentation is built and deployed
Delivery Journey - New Source
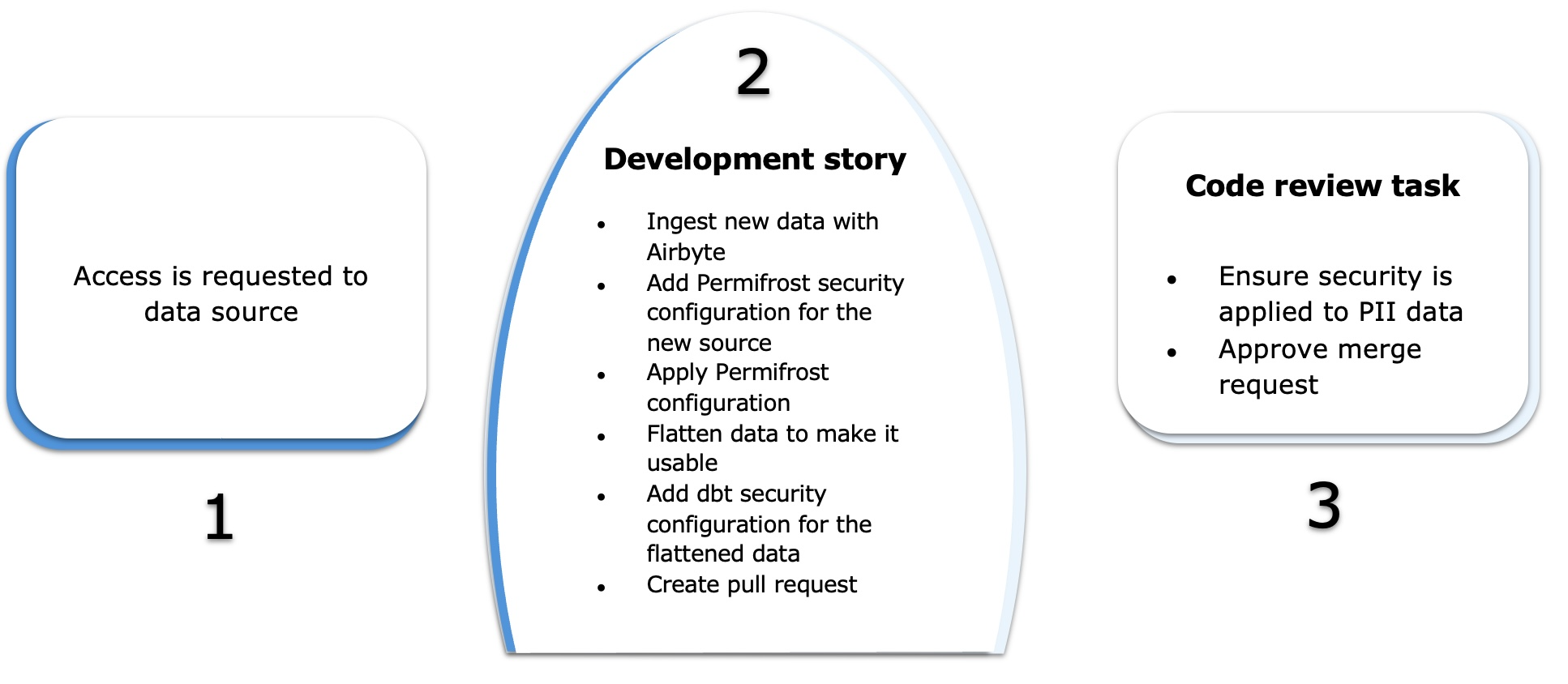
-
Source Credentials
- Access is requested to data source system
-
Development story:
- Use AirByte, Fivetran or other ingestion tool to extract and load raw data from the new source into Snowflake
- Add Permifrost security config for the new source in raw database
- Apply permifrost config to grant developers access to raw source tables
- Create any flattening required to make the data usable
- Add dbt security configuration like masking policies to the flattened models
- Create pull request to deploy the new source to production
-
Code review task:
- Ensure security is applied to PII/Sensitive data
- Approve merge request
Ongoing Processes
Before a story is added to development backlog:
- Check sources are available in Snowflake for story or add story to ingest new data
- Initial discovery of data is performed to understand the data and determine what steps may be required to deliver the requested output. Any data model design is agreed and work is broken up into sprint tasks
- Assure any other requirements are well defined in story e.g. column descriptions, model layout, required tests, etc.